Hi there, and welcome. This content is still relevant, but fairly old. If you are interested in keeping up-to-date with similar articles on profiling, performance testing, and writing performant code, consider signing up to the Four Steps to Faster Software newsletter. Thanks!
Monitoring of various metrics is a large part of ensuring that our systems are behaving in the way that we expect. For low-latency systems in particular, we need to be able to develop an understanding of where in the system any latency spikes are occurring.
Ideally, we want to be able to detect and diagnose a problem before it's noticed by any of our customers. In order to do this, at LMAX Exchange we have developed extensive tracing capabilities that allow us to inspect request latency at many different points in our infrastructure.
This (often) helps us to narrow down the source of a problem to something along the lines of "a cache battery has died on host A, so disk writes are causing latency spikes". Sometimes of course, there's no such easy answer, and we need to take retrospective action to improve our monitoring when we find a new and interesting problem.
One such problem occurred in our production environment a few months ago. This was definitely one of the cases where we couldn't easily identify the root cause of the issue. Our only symptom was that order requests were being processed much slower than expected.
Since we rebuilt and tuned our exchange, our latencies have been so good that in this case we were able to detect the problem before any of our users complained about a deterioration in performance. Even though we could see that there was a problem, overall latency was still within our SLAs.
In order to describe the symptom we observed, I'll describe in more detail the in-application monitoring that we use to measure latencies within the core of our system.
For a more comprehensive view of our overall architecture, please refer to previous posts.
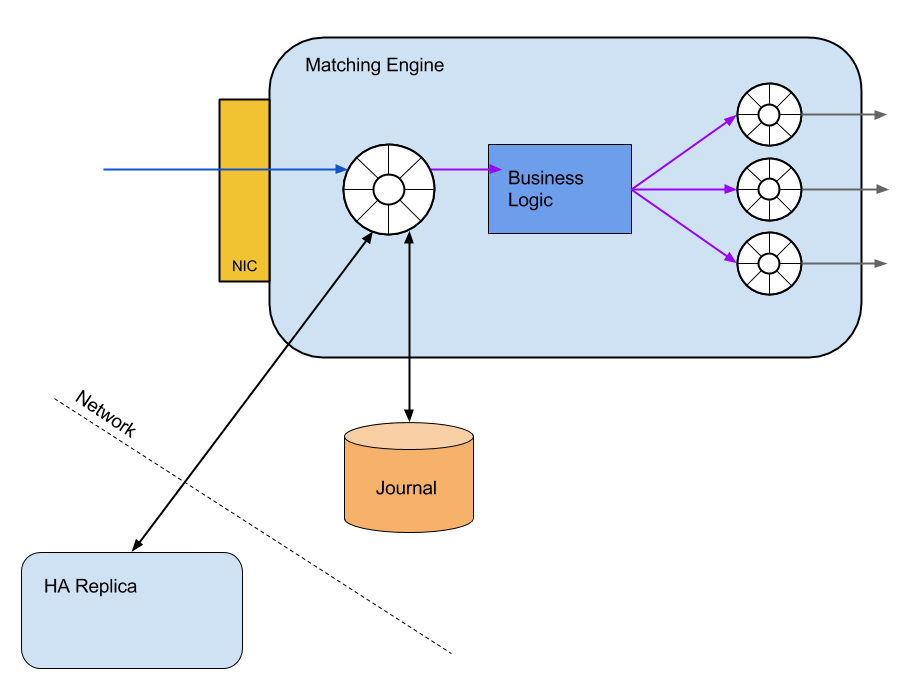
The image below depicts the data-flow through the matching engine at the core of our exchange. Moving from left-to-right, the steps involved in message processing are:
While performing investigation that eventually led to a decent increase in journalling performance, we found that it was extremely useful to instrument our code and monitor exactly how long it was taking to process a message at various points within our matching engine.
This led to a technique whereby we trace the execution time of every message through the service, and report out a detailed breakdown if the total processing time exceeds some reporting threshold.
The image below shows where in the message flow we record nanosecond-precision timestamps during message processing. For more detail on just how precise those timestamps are likely to be, please refer to the mighty Shipilev's 'Nanotrusting the Nanotime'.
For the purposing of our monitoring, what we care about is that System.nanoTime() calls are cheap. Due to this property, we can perform very low-overhead monitoring all the time, and only report out detail when something interesting happens, such as a threshold being triggered.
We classify two types of processing duration within the matching engine:
- 'infrastructure' duration, which is the time taken between message receipt from the network, and the business logic beginning to execute. This includes the time taken to journal and replicate synchronously to the secondary. As such, it is a good indicator of problems external to the application.
- 'logic' duration, which is the time taken from the start of logic execution until processing of that particular message is complete.
Within the logic duration, we also have a breakdown of the time taken between each published outbound message, which we will refer to as 'inter-publish' latency. Consider some example order-matching logic:
In this example, transactionReporter and tradeReporter are both proxies to a publisher ring-buffer. Given our instrumented trace-points in the code, we can determine how long it took the intervening methods to execute (the 'inter-publish' latency).
Now if we consider the scenario where due to a code or data change, the time taken to execute engine.updateAggregateOrderStatistics() has dramatically increased (enough to trip the reporting threshold), we will have the necessary information to pinpoint this function as the culprit.
This monitoring capability has proved to be extremely useful in tracking down a number of performance issues, some of which have been very difficult to replicate in performance environments.
In addition to reporting out detailed information when a threshold is triggered, we also utilise the recorded data and report some aggregated metrics every second. This can be a valuable tool in detecting modal changes in behaviour over time, for example after a new code release.
The first change in behaviour we noticed was the mean average 'logic' time per-second. This is calculated by summing total logic time within a second and dividing by the number of messages processed. Now, we all know that relying on averages for anything is evil, but they do have a use when comparing overall behaviour.
Below is a screen-grab of a chart comparing our average logic processing time (blue) to the same metric from the previous week (green). In this chart, lower is better, so we could see that there had been a clear regression in performance at some point in the last week.
This regression was not evident in any of our other production environments, nor possible to replicate in performance environments.
Given that the average logic time was increased, it followed that the per-request logic time had also increased. Careful comparison of data from different environments running the same code release showed us that our 'inter-publish' latency was up to 15x higher in the affected environment.
After making this comparison, we were fairly sure that this problem was environmental, as the inter-publish latencies are recorded during the execution of a single thread, without locks or I/O of any kind. Since the execution is all in-memory, we were unable to come up with a scenario in which the code would run slower in one environment compared to another, given that the systems were running on identical hardware.
One data item we did have was the fact that we had performed a code release over the previous weekend. This pointed towards a code change of some sort, that did not affect all instances of the matching engine equally.
Looking at the code changes released at the weekend, we could see that one of the most major changes was a different WaitStrategy that we were using in our main application Disruptor instances. We had deployed a hybrid implementation that merged the behaviour of both the BusySpinWaitStrategy (for lowest inter-thread latency) and the TimeoutBlockingWaitStrategy (for time-out events when the ring-buffer is empty).
The implementation of our TimeoutBusySpinWaitStrategy involved some busy-spinning for a set number of loops, followed by a poll of System.nanoTime() to check whether the time-out period has elapsed. This change meant that we were making 1000s of extra calls to System.nanoTime() every second.
This in itself seemed fairly innocuous - the change had passed through our performance environment without any hint of regression, but the evidence pointed towards some kind of contention introduced with a higher frequency of nanoTime calls. This hypothesis was backed up by the fact that our inter-publish latency was higher - if we consider that in order to calculate this latency, we need to call System.nanoTime().
So, if there is some kind of contention in retrieving the timestamp, and we have massively increased the rate at which we are making the call, then we would expect to see an increase in processing times, due to the recording of inter-publish latency.
Given our theory that the calls to System.nanoTime() are taking longer than usual in this particular environment, we starting digging a bit deeper on the box in question. Very quickly, we found the relevant line in the syslog:
WARNING: Clocksource tsc unstable (delta = XXXXXX ns)
followed a little later by:
WARNING: CPU: 27 PID: 2470 at kernel/time/tick-sched.c:192 can_stop_full_tick+0x13b/0x200()
NO_HZ FULL will not work with unstable sched clock
So now we had a hint that the clocksource had changed on that machine. Comparing the clocksource on all other machines showed that the affected host was using the hpet clocksource instead of tsc.
To view the available and currently-selected clocksources on a Linux machine, consult the following files:
/sys/devices/system/clocksource/clocksource0/available_clocksource
/sys/devices/system/clocksource/clocksource0/current_clocksource
Before making any changes or deploying fixes, we wanted to make sure that we definitely understood the problem at hand. To test our theory it was a simple matter to design an experiment that would replicate the change in behaviour due to the code release: create a thread that continuously calls System.nanoTime(), recording the time taken between two calls; scale up a number of worker threads that are just calling System.nanoTime() many times per second.
There is a small application on Github to do exactly this, and it clearly demonstrates the difference between clock sources.
When the clocksource is tsc, calls to retrieve the system nanoseconds have a granularity of ~25ns. Increasing the number of threads does not seem to impact this number a great deal.
java -jar ./nanotiming-all-0.0.1.jar 0
Measuring time to invoke System.nanoTime() with 0 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: tsc
15:14:02.861 avg. time between calls to System.nanoTime() 25ns
15:14:03.760 avg. time between calls to System.nanoTime() 25ns
15:14:04.760 avg. time between calls to System.nanoTime() 25ns
15:14:05.760 avg. time between calls to System.nanoTime() 25ns
Ideally, we want to be able to detect and diagnose a problem before it's noticed by any of our customers. In order to do this, at LMAX Exchange we have developed extensive tracing capabilities that allow us to inspect request latency at many different points in our infrastructure.
This (often) helps us to narrow down the source of a problem to something along the lines of "a cache battery has died on host A, so disk writes are causing latency spikes". Sometimes of course, there's no such easy answer, and we need to take retrospective action to improve our monitoring when we find a new and interesting problem.
One such problem occurred in our production environment a few months ago. This was definitely one of the cases where we couldn't easily identify the root cause of the issue. Our only symptom was that order requests were being processed much slower than expected.
Since we rebuilt and tuned our exchange, our latencies have been so good that in this case we were able to detect the problem before any of our users complained about a deterioration in performance. Even though we could see that there was a problem, overall latency was still within our SLAs.
Measuring, not sampling
In order to describe the symptom we observed, I'll describe in more detail the in-application monitoring that we use to measure latencies within the core of our system.
For a more comprehensive view of our overall architecture, please refer to previous posts.
The image below depicts the data-flow through the matching engine at the core of our exchange. Moving from left-to-right, the steps involved in message processing are:
- Message arrives from the network
- Message is copied into an in-memory ring-buffer (a Disruptor instance)
- In parallel, the message is replicated to a secondary, and journalled to disk
- Once replicated, the message is handled by the application thread, executing business logic
- The business logic will publish zero-to-many response messages into publisher ring-buffers
- A consumer thread for each publisher ring-buffer will write outbound messages to the network
Message processing in the matching engine
While performing investigation that eventually led to a decent increase in journalling performance, we found that it was extremely useful to instrument our code and monitor exactly how long it was taking to process a message at various points within our matching engine.
This led to a technique whereby we trace the execution time of every message through the service, and report out a detailed breakdown if the total processing time exceeds some reporting threshold.
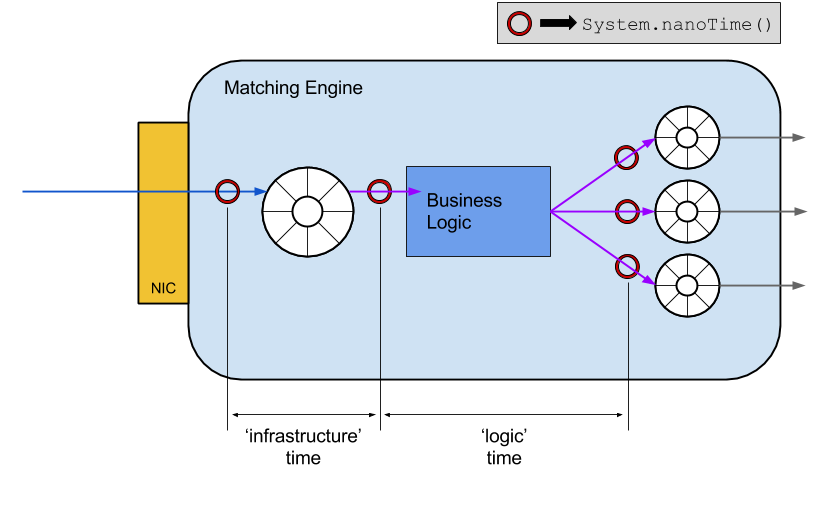
The image below shows where in the message flow we record nanosecond-precision timestamps during message processing. For more detail on just how precise those timestamps are likely to be, please refer to the mighty Shipilev's 'Nanotrusting the Nanotime'.
Recording 'infrastructure' and 'logic' processing times
For the purposing of our monitoring, what we care about is that System.nanoTime() calls are cheap. Due to this property, we can perform very low-overhead monitoring all the time, and only report out detail when something interesting happens, such as a threshold being triggered.
We classify two types of processing duration within the matching engine:
- 'infrastructure' duration, which is the time taken between message receipt from the network, and the business logic beginning to execute. This includes the time taken to journal and replicate synchronously to the secondary. As such, it is a good indicator of problems external to the application.
- 'logic' duration, which is the time taken from the start of logic execution until processing of that particular message is complete.
Within the logic duration, we also have a breakdown of the time taken between each published outbound message, which we will refer to as 'inter-publish' latency. Consider some example order-matching logic:
In this example, transactionReporter and tradeReporter are both proxies to a publisher ring-buffer. Given our instrumented trace-points in the code, we can determine how long it took the intervening methods to execute (the 'inter-publish' latency).
Now if we consider the scenario where due to a code or data change, the time taken to execute engine.updateAggregateOrderStatistics() has dramatically increased (enough to trip the reporting threshold), we will have the necessary information to pinpoint this function as the culprit.
This monitoring capability has proved to be extremely useful in tracking down a number of performance issues, some of which have been very difficult to replicate in performance environments.
The symptom
In addition to reporting out detailed information when a threshold is triggered, we also utilise the recorded data and report some aggregated metrics every second. This can be a valuable tool in detecting modal changes in behaviour over time, for example after a new code release.
The first change in behaviour we noticed was the mean average 'logic' time per-second. This is calculated by summing total logic time within a second and dividing by the number of messages processed. Now, we all know that relying on averages for anything is evil, but they do have a use when comparing overall behaviour.
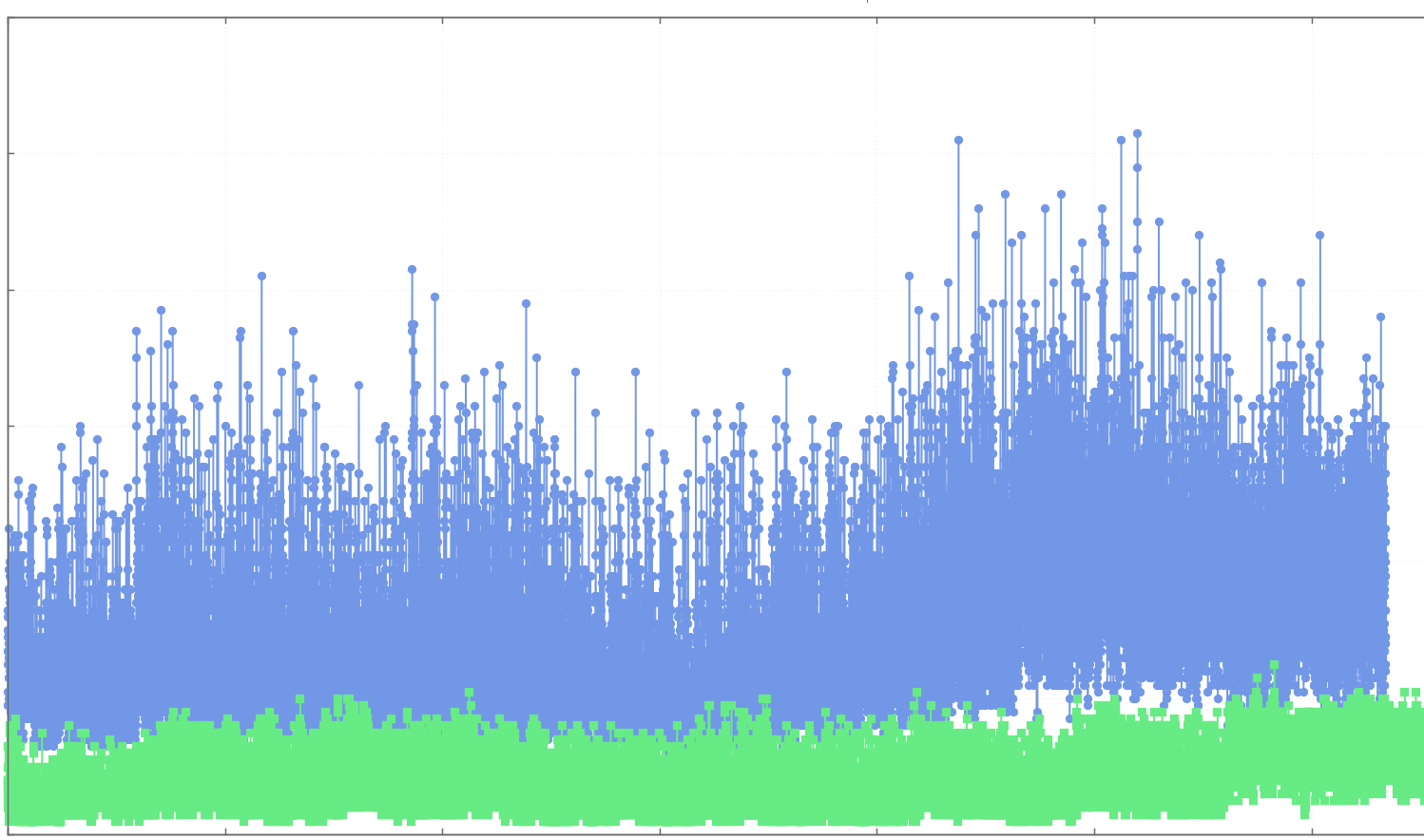
Below is a screen-grab of a chart comparing our average logic processing time (blue) to the same metric from the previous week (green). In this chart, lower is better, so we could see that there had been a clear regression in performance at some point in the last week.
Comparing the change in average logic time
This regression was not evident in any of our other production environments, nor possible to replicate in performance environments.
Given that the average logic time was increased, it followed that the per-request logic time had also increased. Careful comparison of data from different environments running the same code release showed us that our 'inter-publish' latency was up to 15x higher in the affected environment.
After making this comparison, we were fairly sure that this problem was environmental, as the inter-publish latencies are recorded during the execution of a single thread, without locks or I/O of any kind. Since the execution is all in-memory, we were unable to come up with a scenario in which the code would run slower in one environment compared to another, given that the systems were running on identical hardware.
One data item we did have was the fact that we had performed a code release over the previous weekend. This pointed towards a code change of some sort, that did not affect all instances of the matching engine equally.
A complicating factor
Looking at the code changes released at the weekend, we could see that one of the most major changes was a different WaitStrategy that we were using in our main application Disruptor instances. We had deployed a hybrid implementation that merged the behaviour of both the BusySpinWaitStrategy (for lowest inter-thread latency) and the TimeoutBlockingWaitStrategy (for time-out events when the ring-buffer is empty).
The implementation of our TimeoutBusySpinWaitStrategy involved some busy-spinning for a set number of loops, followed by a poll of System.nanoTime() to check whether the time-out period has elapsed. This change meant that we were making 1000s of extra calls to System.nanoTime() every second.
This in itself seemed fairly innocuous - the change had passed through our performance environment without any hint of regression, but the evidence pointed towards some kind of contention introduced with a higher frequency of nanoTime calls. This hypothesis was backed up by the fact that our inter-publish latency was higher - if we consider that in order to calculate this latency, we need to call System.nanoTime().
So, if there is some kind of contention in retrieving the timestamp, and we have massively increased the rate at which we are making the call, then we would expect to see an increase in processing times, due to the recording of inter-publish latency.
The root cause
Given our theory that the calls to System.nanoTime() are taking longer than usual in this particular environment, we starting digging a bit deeper on the box in question. Very quickly, we found the relevant line in the syslog:
WARNING: Clocksource tsc unstable (delta = XXXXXX ns)
followed a little later by:
WARNING: CPU: 27 PID: 2470 at kernel/time/tick-sched.c:192 can_stop_full_tick+0x13b/0x200()
NO_HZ FULL will not work with unstable sched clock
So now we had a hint that the clocksource had changed on that machine. Comparing the clocksource on all other machines showed that the affected host was using the hpet clocksource instead of tsc.
To view the available and currently-selected clocksources on a Linux machine, consult the following files:
/sys/devices/system/clocksource/clocksource0/available_clocksource
/sys/devices/system/clocksource/clocksource0/current_clocksource
Experimentation and verification
Before making any changes or deploying fixes, we wanted to make sure that we definitely understood the problem at hand. To test our theory it was a simple matter to design an experiment that would replicate the change in behaviour due to the code release: create a thread that continuously calls System.nanoTime(), recording the time taken between two calls; scale up a number of worker threads that are just calling System.nanoTime() many times per second.
There is a small application on Github to do exactly this, and it clearly demonstrates the difference between clock sources.
When the clocksource is tsc, calls to retrieve the system nanoseconds have a granularity of ~25ns. Increasing the number of threads does not seem to impact this number a great deal.
java -jar ./nanotiming-all-0.0.1.jar 0
Measuring time to invoke System.nanoTime() with 0 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: tsc
15:14:02.861 avg. time between calls to System.nanoTime() 25ns
15:14:03.760 avg. time between calls to System.nanoTime() 25ns
15:14:04.760 avg. time between calls to System.nanoTime() 25ns
15:14:05.760 avg. time between calls to System.nanoTime() 25ns
java -jar ./nanotiming-all-0.0.1.jar 4
Measuring time to invoke System.nanoTime() with 4 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: tsc
15:14:58.751 avg. time between calls to System.nanoTime() 25ns
15:14:59.730 avg. time between calls to System.nanoTime() 25ns
15:15:00.730 avg. time between calls to System.nanoTime() 25ns
15:15:01.730 avg. time between calls to System.nanoTime() 25ns
java -jar ./nanotiming-all-0.0.1.jar 16
Measuring time to invoke System.nanoTime() with 16 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: tsc
15:16:17.637 avg. time between calls to System.nanoTime() 27ns
15:16:18.616 avg. time between calls to System.nanoTime() 29ns
15:16:19.616 avg. time between calls to System.nanoTime() 29ns
15:16:20.616 avg. time between calls to System.nanoTime() 30ns
Things look somewhat worse once we are using the hpet clocksource.
echo hpet > /sys/devices/system/clocksource/clocksource0/current_clocksource
java -jar ./nanotiming-all-0.0.1.jar 0
Measuring time to invoke System.nanoTime() with 0 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: hpet
15:19:00.029 avg. time between calls to System.nanoTime() 612ns
15:19:01.267 avg. time between calls to System.nanoTime() 675ns
15:19:02.267 avg. time between calls to System.nanoTime() 610ns
15:19:03.267 avg. time between calls to System.nanoTime() 610ns
java -jar ./nanotiming-all-0.0.1.jar 4
Measuring time to invoke System.nanoTime() with 4 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: hpet
15:19:24.522 avg. time between calls to System.nanoTime() 1443ns
15:19:25.498 avg. time between calls to System.nanoTime() 1451ns
15:19:26.498 avg. time between calls to System.nanoTime() 1438ns
15:19:27.497 avg. time between calls to System.nanoTime() 1443ns
java -jar ./nanotiming-all-0.0.1.jar 16
Measuring time to invoke System.nanoTime() with 16 contending threads.
Available logical CPUs on this machine: 32
Current clocksource is: hpet
15:19:44.542 avg. time between calls to System.nanoTime() 7949ns
15:19:45.465 avg. time between calls to System.nanoTime() 7466ns
15:19:46.464 avg. time between calls to System.nanoTime() 9202ns
15:19:47.464 avg. time between calls to System.nanoTime() 7082ns
The tsc clock source seems to scale perfectly with a number of competing threads attempting to read the time. This stands to reason, as the tsc clock reads the CPU-local Time Stamp Counter, and so there is no contention.
The hpet clock, apart from being slower by 20x even when uncontended, does not scale with contending threads, so calls to System.nanoTime() take longer as more threads try to read the current timestamp.
This notable difference is due to the hpet clock being provided to the kernel as memory-mapped I/O, rather than a CPU-local register read.
While investigating this problem and in trying to understand why hpet was so much slower and more prone to contention, the only reference to the phenomenon that I could find was this quote:
"I'm quite sure that you are staring at the HPET scalability bottleneck
and not at some actual kernel bug."
In some circles, this is obviously a known issue.
Application developers who happily sprinkle calls to System.nanoTime() (or the equivalent gettime(CLOCK_MONOTONIC) call in other languages) around their code should be aware that these calls could be more costly than expected.
The Fix
Having identified the problem, we were keen to roll out a fix - surely we could just switch back to the tsc clocksource? Unfortunately, once the kernel watchdog has marked the clocksource as unstable, it is removed from the list of available clocksources. In this case, we had to wait until the following weekend to switch out the hardware before the problem was properly solved.
Longer-term, how can we ensure that we don't have the same problem if the kernel once again determines that the tsc clock is unstable? Since we use Azul's Zing JVM at LMAX, we were able to take advantage of their -XX:+UseRdtsc runtime flag, which forces the runtime to intrinsify System.nanoTime() calls to a direct read of the local TSC, rather than going through the kernel's gettime vdso.
This neatly side-steps the problem if you're running Zing, but on Oracle/OpenJDK there is no such flag.
Conclusion
Good monitoring strategies require precise and accurate timestamping capabilities in order to correctly measure latencies. Using System.nanoTime() is the recommended way to sample an accurate timestamp from Java. Depending on the clock in use by the (Linux) system under test, actual timestamp granularity may vary wildly.
As usual, digging down through the layers of abstraction provided by various libraries and virtual machines has proven to be a valuable experience. Through the application of scientific principles and ensuring that problems are repeatable and understood, we can more successfully reason about what is actually happening in these complex machines that run our software.
Follow @epickrram
Follow @epickrram