Hi there, and welcome. This content is still relevant, but fairly old. If you are interested in keeping up-to-date with similar articles on profiling, performance testing, and writing performant code, consider signing up to the Four Steps to Faster Software newsletter. Thanks!
Update
Amir has very kindly contributed a Vagrant box configuration to enable non-Linux users to work with the tools contained in the grav repository.
Thanks Amir!
In my last post, I looked at annotating Flamegraphs with contextual information in order to filter on an interesting subset of the data. One of the things that stuck with me was the idea of using SVGs to render data generated on a server running in headless mode.
Traditionally, I have recorded profiles and traces on remote servers, then pulled the data back to my workstation to filter, aggregate and plot. The scripts used to do this data-wrangling tend to be one-shot affairs, and I've probably lost many useful utilities over the years. I am increasingly coming around to the idea of building the rendering into the server-side script, as it forces me to think about how I want to interpret the data, and also gives the ability to deploy and serve such monitoring from a whole fleet of servers.
Partly to address this, and partly because experimentation is fun, I've been working on some new visualisations of the same ilk as Flamegraphs.
These tools are available in the grav repository.
Scheduler Profile
The scheduler profile tool can be used to indicate whether your application's threads are getting enough time on CPU, or whether there is resource contention at play.In an ideal scenario, your application threads will only ever yield the CPU to one of the kernel's helper threads, such as
ksoftirqd, and then only sparingly. Running the scheduling-profile script will record scheduler events in the kernel and will determine the state of your application threads at the point they are pre-empted and replaced with another process.Threads will tend to be in one of three states when pre-empted by the scheduler:
- Runnable - happily doing work, moved off the CPU due to scheduler quantum expiry (we want to minimise this)
- Blocked on I/O - otherwise known as 'Uninterruptible sleep', still an interesting signal but expected for threads handling IO
- Sleeping - voluntarily yielding the CPU, perhaps due to waiting on a lock
Once the profile is collected, these states are rendered as a bar chart for each thread in your application. The examples here are from a JVM-based service, but the approach will work just as well for other runtimes, albeit without the mapping of
pid to thread name.The bar chart will show the proportion of states encountered per-thread as the OS scheduler swapped out the application thread. The
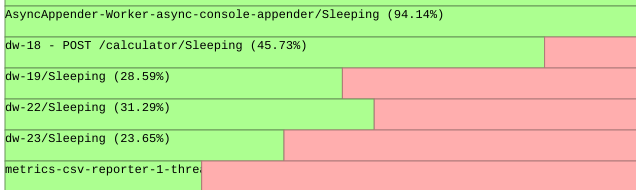
sleeping state is marked green (the CPU was intentionally yielded), the runnable state is marked red (the program thread was pre-empted while it still had useful work to do).Let's take a look at an initial example running on my 4-core laptop:
original
{kind=link}
This profile is taken from a simple drop-wizard application, the threads actually processing inbound requests are prefixed with
'dw-'. We can see that these request processing threads were ready to yield the CPU (i.e. entering sleep state) about 30% of the time, but they were mostly attempting to do useful work when they were moved off the CPU. This is a hint that the application is resource constrained in terms of CPU.This effect is magnified due to the fact that I'm running a desktop OS, the application, and a load-generator all on the same laptop, but these effects will still be present on a larger system.
This can be a useful signal that these threads would benefit from their own dedicated pool of CPUs. Further work is needed to annotate the chart with those processes that were switched in by the scheduler - i.e. the processes that are contending with the application for CPU resource.
Using a combination of kernel tuning and thread-pinning, it should be possible to ensure that the application threads are only very rarely pre-empted by essential kernel threads. More details on how to go about achieving this can be found in previous posts.
CPU Tenancy
One of the operating system's responsibilities is to allocate resources to processes that require CPU. In modern multi-core systems, the scheduler must move runnable threads to otherwise idle CPUs to try to maximise system resource usage.A good example if this is network packet handling. When a network packet is received, it is (by default) processed by the CPU that handles the network card's interrupt. The kernel may then decide to migrate any task that is waiting for data to arrive (e.g. a thread blocked on a socket read) to the receiving CPU, since the packet data is more likely to be available in the CPU's cache.
While we can generally rely on the OS to do a good job of this for us, we may wish to force this cache-locality by having a network-handling thread on an adjacent CPU to the interrupt handler. Such a set-up would mean that the network-handling thread would always be close to the data, without the overhead and jitter introduced by actually running on a CPU responsible for handling interrupts.
This is a common configuration in low-latency applications in the finance industry.
The
perf-cpu-tenancy script can be used to build a picture showing how the scheduler allocates CPU to your application threads. In the example below, the threads named dw- are the message-processing threads, and it is clear that they are mostly executed on CPU 2. This correlates with the network card setup on the machine running the application - the IRQ of the network card is associated with CPU 2.
original
{kind=link}
Further work
To make thescheduling-profile tool more useful, I intend to annotate the runnable state portion of the bar chart with a further breakdown detailing the incoming processes that kicked application threads off-CPU.This will provide enough information to direct system-tuning efforts to ensure an application has the best chance possible to get CPU-time when required.
If you've read this far, perhaps you're interested in contributing?
Follow @epickrram