Hi there, and welcome. This content is still relevant,
but fairly old. If you are interested in keeping up-to-date with similar
articles on profiling, performance testing, and writing performant
code, consider signing up to the Four Steps to Faster Software newsletter. Thanks!
In this post, I'm going to talk about traffic analysis and load modelling for performance tests. I will describe in some detail how we went about ensuring that we were accurately modelling production traffic patterns when executing our performance tests. In this post, I will be focussing on the market-maker order flow into our system since it produces the most load and consequently, the most stress on the system.
In order to answer the questions above, we are going to be interested in looking at all inbound messages for a given session. In order to do this, we will be paying attention to the following tags:
First of all, we will isolate all messages for a given session and resource; time to delve into bash...
We are only interested in inbound requests, since they are the messages that we will be replicating when running performance tests. There are four inbound messages that are important: NewOrderSingle (35=D), OrderCancel (35=F), OrderCancelReplace (35=G) and MassQuote (35=i).
Now that we have an interesting set of messages, we can start answering the questions posed above.
What type of messages arrive?
How many messages arrive in a given time interval?
What is the interval of time elapsed between messages?
What resources are used by different types of message?



 Armed with this knowledge, it is possible to create a simulation that will generate traffic closely resembling our source data.
Armed with this knowledge, it is possible to create a simulation that will generate traffic closely resembling our source data.
How well are we modelling the type of message received?

This is pretty good, no calibration needed here. How well are we modelling the arrival rate of messages?
This comparison is deliberately omitted, as we run our performance tests at ~10x production load.
How well are we modelling the interval between messages?

Again, pretty good - the overall shape looks about right. The most important thing is that we're sending in messages fast enough (i.e. both histograms have bumps in roughly the same places) How well are we modelling the message distribution over resources?

Not so good, but not necessarily cause for concern. Disclaimer: All charts are for illustrative purposes only; the model in our performance environment is built from analysing more than ten minutes worth of data, so something like resource distribution that changes over the course of the day will not be well represented in a ten minute sample.
Whether this chart matters will depend on your system and business domain - in our exchange, the cost of processing an order instruction is the same for all resources, so as long as there is some representative noise, the model is still valid. Running the analysis over a much longer sample period would produce enough data-points to improve the match between these two datasets, if such a step was required.
The model should be tested to ensure that it is behaving as expected, and that your performance test harness is close enough to reality to provide meaningful results - after all, it's no good testing the wrong thing.
Follow @epickrram
Traffic Analysis
In my previous post, I explained that our market-makers use the FIX protocol to communicate with us. This is an asynchronous request-response protocol using different message types to perform specific actions. In order to correctly model the load on our system, we need to answer a few important questions for each market-maker session:- What types of messages arrive?
- How many messages arrive in a given time interval?
- What is the interval of time elapsed between messages?
- What resources are used by different types of message?
8=FIX.4.2|9=211|35=D|49=session1|56=LMAX-FIX|34=258790|52=20140509-06:36:12.193|22=8|47=P|21=1|54=1|60=20140509-06:36:12.193|59=0|38=10000|40=2|581=1|11=774876524712244|55=GBP/JPY|48=180415|44=148.72674|10=227|
- 49 - SenderCompId - the party sending the message
- 35 - MsgType - the type of message
- 52 - SendingTime - when the message was sent by the client
- 55 - Symbol - the resource to apply the message to (in this case, the financial instrument to be traded)
First of all, we will isolate all messages for a given session and resource; time to delve into bash...
pricem@asset-xxxxx:~$ grep -oE "\|49=[^\|]+" message-log.txt | head -1
|49=session1
pricem@asset-xxxxx:~$ grep session1 message-log.txt > session1-messages.txt
pricem@asset-xxxxx:~$ grep -oE "\|55=[^\|]+" session1-messages.txt | head -1
|55=GBP/USD
pricem@asset-xxxxx:~$ grep "GBP/USD" session1-messages.txt > session1-gbpusd-messages.txt
pricem@asset-xxxxx:~$ grep -E "\|35=(D|F|G|i)" session1-gbpusd-messages.txt > session1-gbpusd-inbound-messages.txt
What type of messages arrive?
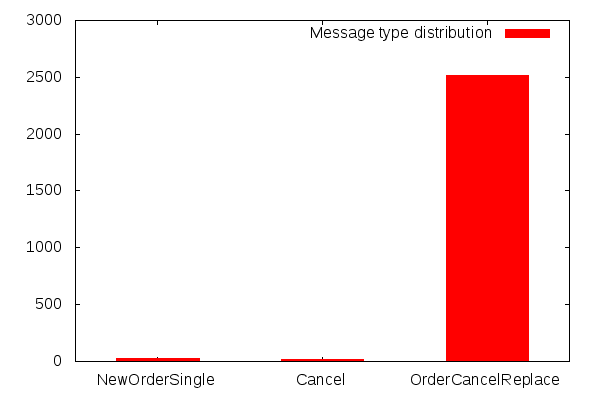
pricem@asset-xxxxx:~$ grep -oE "\|35=[^\|]+" session1-gbpusd-inbound-messages.txt | sort | uniq -c
24 |35=D
19 |35=F
2515 |35=G
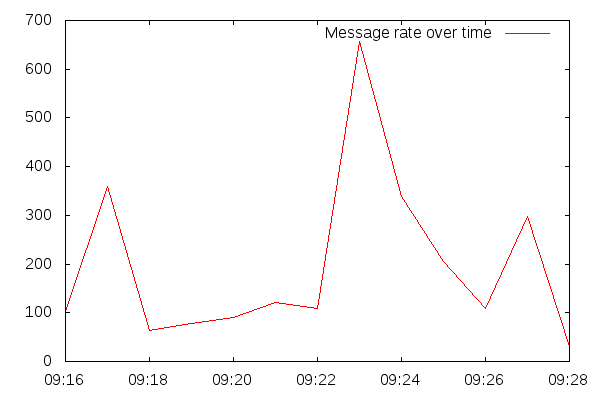
pricem@asset-xxxxx:~$ grep -oE "\|52=[^\|\.]+" session1-gbpusd-inbound-messages.txt | cut -c1-18 | sort | uniq -c
103 |52=20140701-09:16
360 |52=20140701-09:17
63 |52=20140701-09:18
78 |52=20140701-09:19
90 |52=20140701-09:20
121 |52=20140701-09:21
108 |52=20140701-09:22
657 |52=20140701-09:23
338 |52=20140701-09:24
205 |52=20140701-09:25
108 |52=20140701-09:26
297 |52=20140701-09:27
30 |52=20140701-09:28
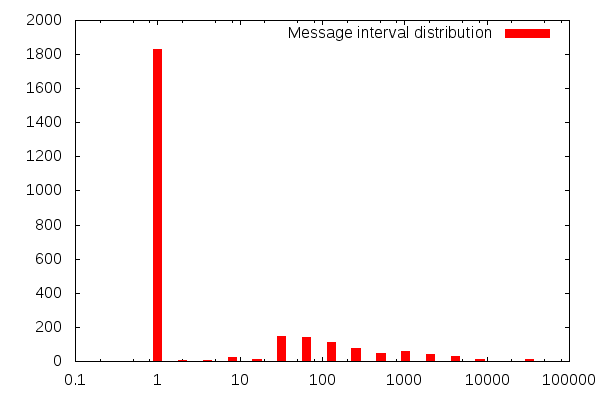
pricem@asset-xxxxx:~$ cat session1-gbpusd-inbound-messages.txt | python ./millisecond_interval_histogram.py
interval, count
0, 1830
2, 7
4, 8
8, 26
16, 13
32, 144
64, 140
128, 111
256, 74
512, 49
1024, 59
2048, 42
4096, 29
8192, 13
32768, 11
65536, 1
pricem@asset-xxxxx:~$ grep -oE "\|55=[^\|\.]+" session1-messages.txt | sort | uniq -c | sort -n
72 |55=EUR/DKK
112 |55=USD/HKD
216 |55=AUD/NZD
...
4128 |55=GBP/ZAR
5142 |55=GBP/USD
7926 |55=USD/TRY
Drawing conclusions
With these data, we can begin to characterise the traffic generated by this session:- Most messages are OrderCancelReplace
- Message arrival rates vary between 30 and 600 messages per minute
- There is a gap of zero milliseconds between most messages, with a gap of 32 - 255 milliseconds between a number of other messages
- Messages are distributed over a number of instruments, some more popular than others

Validating the model
Once your model is up and running in your performance environment, it is vital to measure its effectiveness at simulating production traffic patterns. To do this, simply perform the same analysis on data captured from your performance test environment. Once the analysis is complete, validating the model is easily done by plotting the original numbers against those produced by your model.How well are we modelling the type of message received?
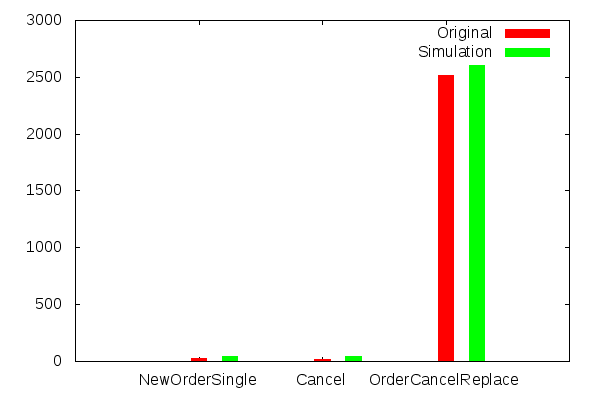
This is pretty good, no calibration needed here. How well are we modelling the arrival rate of messages?
This comparison is deliberately omitted, as we run our performance tests at ~10x production load.
How well are we modelling the interval between messages?
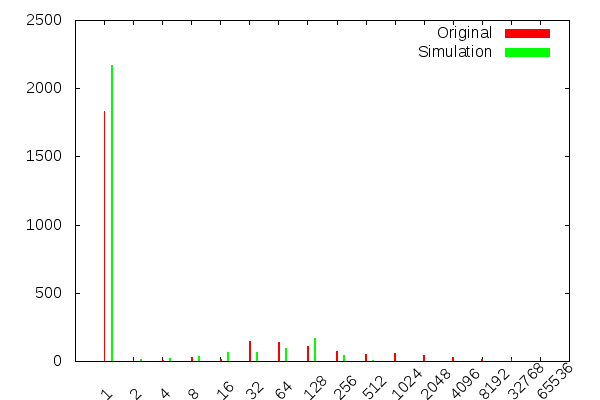
Again, pretty good - the overall shape looks about right. The most important thing is that we're sending in messages fast enough (i.e. both histograms have bumps in roughly the same places) How well are we modelling the message distribution over resources?
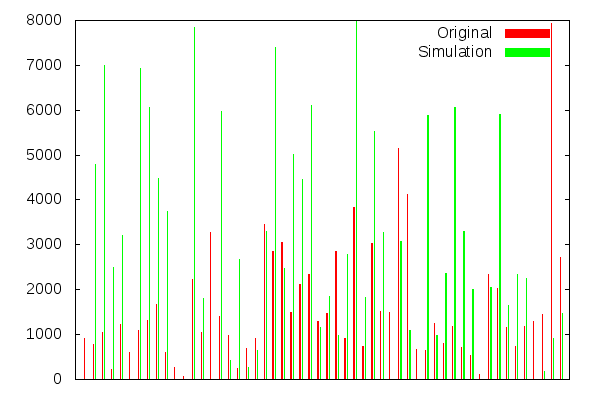
Not so good, but not necessarily cause for concern. Disclaimer: All charts are for illustrative purposes only; the model in our performance environment is built from analysing more than ten minutes worth of data, so something like resource distribution that changes over the course of the day will not be well represented in a ten minute sample.
Whether this chart matters will depend on your system and business domain - in our exchange, the cost of processing an order instruction is the same for all resources, so as long as there is some representative noise, the model is still valid. Running the analysis over a much longer sample period would produce enough data-points to improve the match between these two datasets, if such a step was required.
Wrapping up
When developing a performance-testing strategy, wherever possible, real-world data should be used to generate a model that will create representative load on your system. It is important to understand how your users interact with your system - a naive approach based on guesswork is unlikely to resemble reality. Using charts to visualise different aspects of data flow is a useful tool in developing a mental image, which can help you reason about the model that will need to be built. It can also be handy as a 'sanity-check' to make sure that your analyses are correct.The model should be tested to ensure that it is behaving as expected, and that your performance test harness is close enough to reality to provide meaningful results - after all, it's no good testing the wrong thing.
Follow @epickrram