Hi there, and welcome. This content is still relevant,
but fairly old. If you are interested in keeping up-to-date with similar
articles on profiling, performance testing, and writing performant
code, consider signing up to the Four Steps to Faster Software newsletter. Thanks!
In my last post, I described the benefits of upgrading hardware, operating system and file-system in order to improve the latency of file writes.
After it was published, Martin asked whether we were using FileChannel.write(ByteBuffer, long), which calls the pwrite function, in order to make fewer system calls. We are not currently using this method, though we have experimented with it in the past. Before our recent changes to reduce write latency, we probably didn't notice the overhead of the extra system call due to the background noise on the system.
Since improvements have been made, it is worth re-testing using the pwrite method to see if there is any measurable benefit. We'll get to the numbers later, but first let's just have a look at the difference between the two approaches.
WARNING: Wall of text approaching. If you are averse to JDK source code, you can skip down to "Enough code already".
Our standard journalling technique, that we previously discovered to be the best for latency & throughput, is to write using a RandomAccessFile. The API of RandomAccessFile requires that the programmer set the write position on the file, then call the write method with the data that is to be written.
The call starts in RandomAccessFile.seek, which calls the native method RandomAccessFile.seek0:
Across the JNI bridge in native code, some bounds checking is performed before a call to the utility function IO_Lseek:
IO_Lseek is mapped to the lseek64 system call:
lseek64 is responsible for updating the position of a file offset. See man lseek for more details.
Once we have the pointer in the correct position, then we call the write method. This delegates to the native function RandomAccessFile.writeBytes:
This function then delegates to the utility method IO_Util.writeBytes:
Now we get to the actual work - if your data is greater than 8k in length, a new char[] buffer is allocated using malloc, otherwise a stack buffer is used. The runtime then copies data from the java byte array to the native buffer, and the result is passed on to IO_Write.
IO_Write is mapped to handleWrite, which finally calls the kernel's write function:
Performing a direct write with FileChannel.write is quite different by comparison. After a quick check to see that the file is open, it's straight off the the JDK-internal IOUtil class:
Here we can see the benefit of using a DirectBuffer (assigned with ByteBuffer.allocateDirect() or FileChannel.map()). If you're using an on-heap ByteBuffer, then the runtime will copy your data to a pooled DirectBuffer before attempting to continue:
Next in the chain is FileDispatcherImpl, an implementation of NativeDispatcher, which calls the native function pwrite0:
This function is simply a wrapper around the native pwrite64 call:
See man pwrite64 for more details.
The two call-chains can be summarised as:
RandomAccessFile.seek (java)
-> RandomAccessFile.seek0 (native)
-> lseek (syscall)
RandomAccessFile.write (java)
-> RandomAccessFile.writeBytes (native)
-> io_util#writeBytes (native)
bounds check
allocate buffer if payload > 8k
copy data to buffer
-> io_util#handleWrite (native)
-> write (syscall)
FileChannelImpl.write (java)
-> IOUtil.write (java)
copy to direct buffer if necessary
-> FileDispatcherImpl.pwrite (java)
-> FileDispatcherImpl.pwrite0 (native)
-> pwrite (syscall)
So it certainly seems as though the direct write method should be faster - fewer system calls, and less copying of data (assuming that a DirectBuffer is used in the JVM).
CPUs were isolated to reduce scheduling jitter, though I didn't go as far as thread-pinning. I assume that 20 measurement iterations is enough to weed out jitter caused by the scheduler.
Why tmpfs? Since this is a micro-benchmark, I wanted to test just the code path, separated from the underlying storage medium. If there is a significant difference, then this is something to try on a real file-system, under real load.
Since a picture paints a thousand words, and I've already written far too many for one post, let's have a look at some numbers:



Using FileChannel.write(ByteBuffer, long) in order to perform file operations should result in better performance, with less jitter.
The cost of any computation done in the JDK classes for I/O appears to be overshadowed by the cost of JNI/syscall overhead.
These results were generated using an artificial workload, on a memory-based filesystem, so should be viewed as best-possible results. Results for real-world workloads may vary....
In the near future, I'll make this change in our performance environment and do the same measurements in order to observe the effects of such a change in a real system. Results will be published when I have them.
Thanks to Mike Barker for reviewing my benchmark code. Any remaining mistakes are wholly my own!
Follow @epickrram
After it was published, Martin asked whether we were using FileChannel.write(ByteBuffer, long), which calls the pwrite function, in order to make fewer system calls. We are not currently using this method, though we have experimented with it in the past. Before our recent changes to reduce write latency, we probably didn't notice the overhead of the extra system call due to the background noise on the system.
Since improvements have been made, it is worth re-testing using the pwrite method to see if there is any measurable benefit. We'll get to the numbers later, but first let's just have a look at the difference between the two approaches.
WARNING: Wall of text approaching. If you are averse to JDK source code, you can skip down to "Enough code already".
Seek...
Our standard journalling technique, that we previously discovered to be the best for latency & throughput, is to write using a RandomAccessFile. The API of RandomAccessFile requires that the programmer set the write position on the file, then call the write method with the data that is to be written.
The call starts in RandomAccessFile.seek, which calls the native method RandomAccessFile.seek0:
Across the JNI bridge in native code, some bounds checking is performed before a call to the utility function IO_Lseek:
IO_Lseek is mapped to the lseek64 system call:
lseek64 is responsible for updating the position of a file offset. See man lseek for more details.
... then write
Once we have the pointer in the correct position, then we call the write method. This delegates to the native function RandomAccessFile.writeBytes:
This function then delegates to the utility method IO_Util.writeBytes:
Now we get to the actual work - if your data is greater than 8k in length, a new char[] buffer is allocated using malloc, otherwise a stack buffer is used. The runtime then copies data from the java byte array to the native buffer, and the result is passed on to IO_Write.
IO_Write is mapped to handleWrite, which finally calls the kernel's write function:
Direct write
Performing a direct write with FileChannel.write is quite different by comparison. After a quick check to see that the file is open, it's straight off the the JDK-internal IOUtil class:
Here we can see the benefit of using a DirectBuffer (assigned with ByteBuffer.allocateDirect() or FileChannel.map()). If you're using an on-heap ByteBuffer, then the runtime will copy your data to a pooled DirectBuffer before attempting to continue:
Next in the chain is FileDispatcherImpl, an implementation of NativeDispatcher, which calls the native function pwrite0:
This function is simply a wrapper around the native pwrite64 call:
See man pwrite64 for more details.
Enough code already
The two call-chains can be summarised as:
seek/write
RandomAccessFile.seek (java)
-> RandomAccessFile.seek0 (native)
-> lseek (syscall)
RandomAccessFile.write (java)
-> RandomAccessFile.writeBytes (native)
-> io_util#writeBytes (native)
bounds check
allocate buffer if payload > 8k
copy data to buffer
-> io_util#handleWrite (native)
-> write (syscall)
pwrite
FileChannelImpl.write (java)
-> IOUtil.write (java)
copy to direct buffer if necessary
-> FileDispatcherImpl.pwrite (java)
-> FileDispatcherImpl.pwrite0 (native)
-> pwrite (syscall)
So it certainly seems as though the direct write method should be faster - fewer system calls, and less copying of data (assuming that a DirectBuffer is used in the JVM).
Is it faster?
Benchmarks. They're dangerous. As has been pointed out on numerous occasions, any results you get from benchmarks should be taken with a pinch of salt, and will not necessarily represent the measurements you think that they do.
Before jumping with both feet, and replacing our journaller implementation, I thought I would try to isolate the change with a small benchmark that performs a similar workload to our exchange, with the ability to swap out the implementation of the write call.
Code is available here.
These tests were run on a Dell PowerEdge R720xd, tmpfs file system with flags 'noatime', with arguments:
java -jar journalling-benchmark-all-0.0.1.jar -i 50 -d /mnt/jnl -f SHORT -t pwrite -w 20
java -jar journalling-benchmark-all-0.0.1.jar -i 50 -d /mnt/jnl -f SHORT -t pwrite -w 20
CPUs were isolated to reduce scheduling jitter, though I didn't go as far as thread-pinning. I assume that 20 measurement iterations is enough to weed out jitter caused by the scheduler.
Why tmpfs? Since this is a micro-benchmark, I wanted to test just the code path, separated from the underlying storage medium. If there is a significant difference, then this is something to try on a real file-system, under real load.
Since a picture paints a thousand words, and I've already written far too many for one post, let's have a look at some numbers:
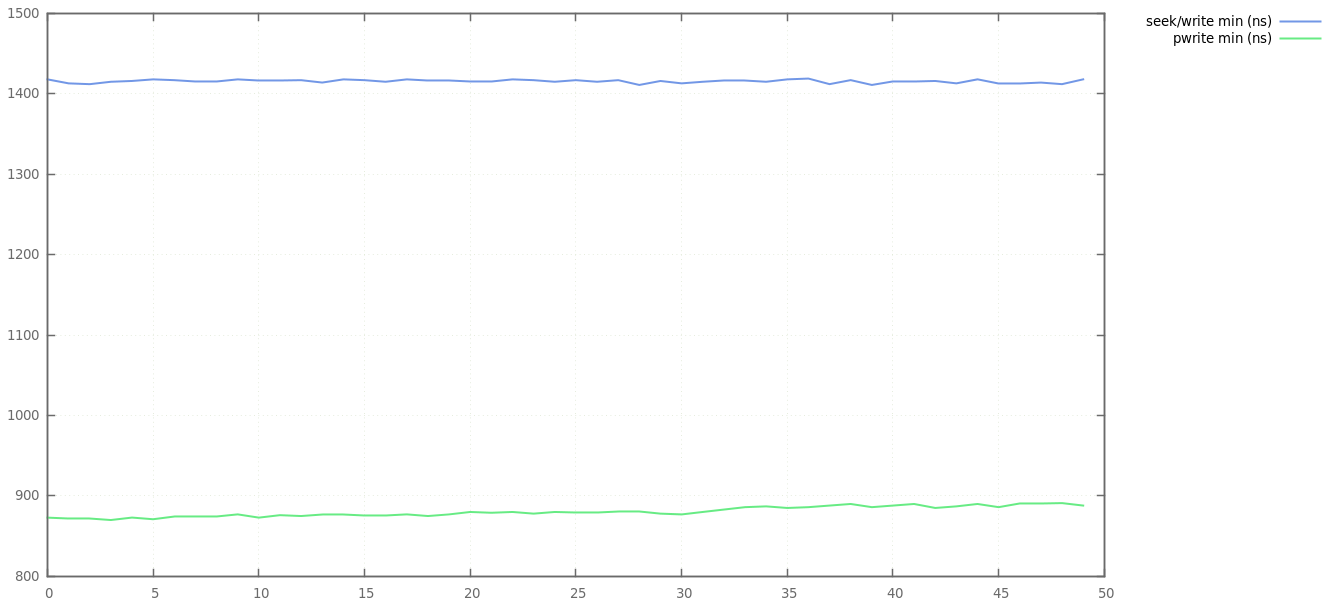
Min write latency
Min write latency is ~900ns for pwrite, ~1400ns for seek/write - this is explained by the fact that we do double the work for seek/write (i.e. two JNI calls, two syscalls) compared to pwrite.
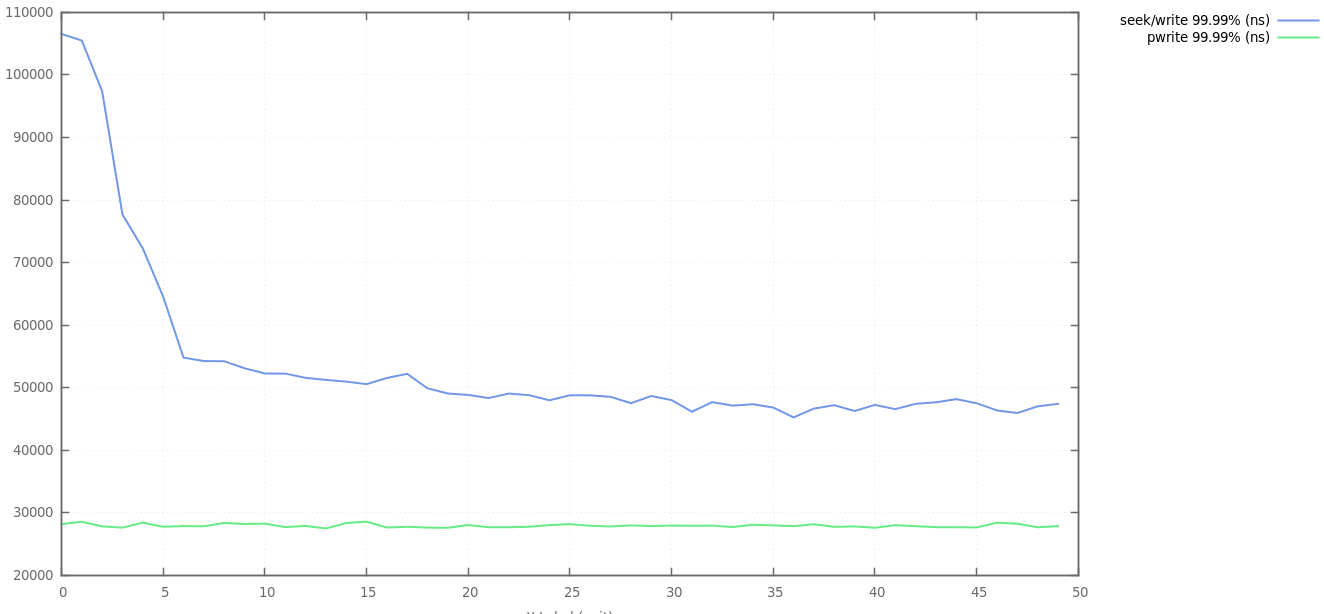
Four-nines write latency
Apart from the obvious warm-up issue in seek/write, it looks as though at the four-nines, pwrite is solid at ~30us, seek/write stabilises at ~50us.
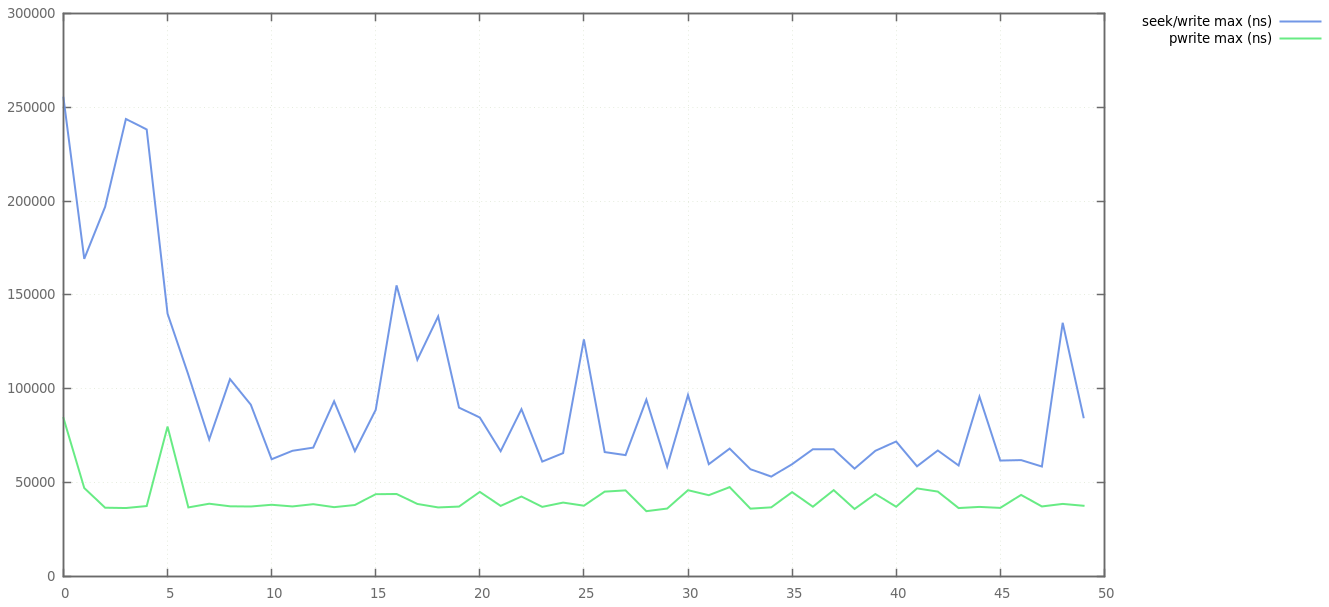
Max write latency
Maximum write latency is where pwrite really shines - there is far less jitter with the max ~50us, whereas seek/write suffers from more variability up to 100us. Again, this is probably down to the extra JNI/syscall work. Further work would be needed to figure out why the max time for seek/write is more than double that of pwrite in some cases.
Conclusions
Using FileChannel.write(ByteBuffer, long) in order to perform file operations should result in better performance, with less jitter.
The cost of any computation done in the JDK classes for I/O appears to be overshadowed by the cost of JNI/syscall overhead.
These results were generated using an artificial workload, on a memory-based filesystem, so should be viewed as best-possible results. Results for real-world workloads may vary....
In the near future, I'll make this change in our performance environment and do the same measurements in order to observe the effects of such a change in a real system. Results will be published when I have them.
Thanks to Mike Barker for reviewing my benchmark code. Any remaining mistakes are wholly my own!
Follow @epickrram