Hi there, and welcome. This content is still relevant,
but fairly old. If you are interested in keeping up-to-date with similar
articles on profiling, performance testing, and writing performant
code, consider signing up to the Four Steps to Faster Software newsletter. Thanks!
I have been working on a small tool to measure the effects of system jitter within a JVM; it is a very simple app that measures inter-thread latencies. The tool's primary purpose is to demonstrate the use of linux performance tools such as perf_events and ftrace in finding causes of latency.
Before using this tool for a demonstration, I wanted to make sure that it was going to actually behave in the way I intended. During testing, I seemed to always end up with a max inter-thread latency of around 100us. I diligently got stuck in to investigating with perf_events, but could never detect any jitter at the system level greater than around 50us.
Where was this mysterious extra 50us latency coming from? The first assumption, of course, was that I had made a mistake, so I took some time in looking at the code and doing extra logging. Eventually, I went the whole hog and just ftraced the entire CPU running the thread that I was measuring. Still no sign of system-level jitter that would explain the latency.
In exasperation, I enabled GC logging for the application. Previously, I had not done this as I knew that the application did not produce any garbage after its initial setup, and I also excluded the first sets of results to reduce pollution by warm-up effects.
Lo and behold, the GC log contained the following entries:
2015-08-05T09:11:51.498+0100: 20.204: Total time for which application threads were stopped: 0.0000954 seconds
2015-08-05T09:11:52.498+0100: 21.204: Total time for which application threads were stopped: 0.0000948 seconds
2015-08-05T09:11:56.498+0100: 25.205: Total time for which application threads were stopped: 0.0001147 seconds
2015-08-05T09:12:06.499+0100: 35.206: Total time for which application threads were stopped: 0.0001127 seconds
2015-08-05T09:12:10.499+0100: 39.206: Total time for which application threads were stopped: 0.0000983 seconds
2015-08-05T09:12:11.499+0100: 40.206: Total time for which application threads were stopped: 0.0000900 seconds
2015-08-05T09:12:12.500+0100: 41.206: Total time for which application threads were stopped: 0.0001421 seconds
2015-08-05T09:12:17.500+0100: 46.207: Total time for which application threads were stopped: 0.0000865 seconds
Note the rather suspicious timing of these events - always ~205ms into the second, and ~100us in magnitude.
Now, because I used the extremely useful -XX:+PrintApplicationStoppedTime flag, the log also contained safepoint pauses. Given that I knew my application was not allocating memory, and therefore should not be causing the collector to run, I assumed that these pauses were down to safepoints.
The next useful flag in the set of "Hotspot flags you never knew you needed, until you need them" is -XX:+PrintSafepointStatistics.
With this flag enabled, the output was immediately enlightening:
20.204: no vm operation [...
21.204: no vm operation [...
25.205: no vm operation [...
35.205: no vm operation [...
39.206: no vm operation [...
40.206: no vm operation [...
41.206: no vm operation [...
46.207: no vm operation [...
The timestamps from the safepoint statistics match up perfectly with the entries in the GC log, so I can be sure of my assumption that the pauses are due to safepointing.
A little time spent with your favourite search engine will yield up the information that 'no vm operation' is the output produced when the runtime forced a safepoint.
Further searching revealed that the frequency of these forced safepoints can be controlled with the following flags:
-XX:+UnlockDiagnosticVMOptions -XX:GuaranteedSafepointInterval=300000
This command instructs the runtime to only guarantee a safepoint every 300 seconds, and since the duration of my test is less than that, there should be no forced safepoints. The default interval can be discovered by running the following command:
]$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal 2>&1 | grep Safepoint
intx GuaranteedSafepointInterval = 1000 {diagnostic}
Running my test tool with these settings removed the 100us jitter, so I'm just left with 50us introduced by the OS and hardware.
As mentioned in some of the mailing lists I stumbled across, it's probably not a good idea to stop the JVM from performing cleanup that requires a safepoint. For this testing tool however, it helps to remove a source of uncertainty that was dominating the jitter produced by the OS.
At LMAX we run a number of microbenchmarks to ensure that our code does not suffer any regressions in performance. By their very nature, these tests tend to have a fair amount of noise in terms of single-shot execution time.
I applied the previously mentioned flags to the JVM running the tests; the reduction in the max execution time is clearly displayed in the chart below:

So aside from just being a curiosity for those who like digging into JVM internals, these flags could have a real benefit for reducing noise in benchmark tests.
Tests were performed using Oracle JDK 1.8.0_20.
Follow @epickrram
Before using this tool for a demonstration, I wanted to make sure that it was going to actually behave in the way I intended. During testing, I seemed to always end up with a max inter-thread latency of around 100us. I diligently got stuck in to investigating with perf_events, but could never detect any jitter at the system level greater than around 50us.
Where was this mysterious extra 50us latency coming from? The first assumption, of course, was that I had made a mistake, so I took some time in looking at the code and doing extra logging. Eventually, I went the whole hog and just ftraced the entire CPU running the thread that I was measuring. Still no sign of system-level jitter that would explain the latency.
In exasperation, I enabled GC logging for the application. Previously, I had not done this as I knew that the application did not produce any garbage after its initial setup, and I also excluded the first sets of results to reduce pollution by warm-up effects.
Lo and behold, the GC log contained the following entries:
2015-08-05T09:11:51.498+0100: 20.204: Total time for which application threads were stopped: 0.0000954 seconds
2015-08-05T09:11:52.498+0100: 21.204: Total time for which application threads were stopped: 0.0000948 seconds
2015-08-05T09:11:56.498+0100: 25.205: Total time for which application threads were stopped: 0.0001147 seconds
2015-08-05T09:12:06.499+0100: 35.206: Total time for which application threads were stopped: 0.0001127 seconds
2015-08-05T09:12:10.499+0100: 39.206: Total time for which application threads were stopped: 0.0000983 seconds
2015-08-05T09:12:11.499+0100: 40.206: Total time for which application threads were stopped: 0.0000900 seconds
2015-08-05T09:12:12.500+0100: 41.206: Total time for which application threads were stopped: 0.0001421 seconds
2015-08-05T09:12:17.500+0100: 46.207: Total time for which application threads were stopped: 0.0000865 seconds
Note the rather suspicious timing of these events - always ~205ms into the second, and ~100us in magnitude.
Now, because I used the extremely useful -XX:+PrintApplicationStoppedTime flag, the log also contained safepoint pauses. Given that I knew my application was not allocating memory, and therefore should not be causing the collector to run, I assumed that these pauses were down to safepoints.
The next useful flag in the set of "Hotspot flags you never knew you needed, until you need them" is -XX:+PrintSafepointStatistics.
With this flag enabled, the output was immediately enlightening:
20.204: no vm operation [...
21.204: no vm operation [...
25.205: no vm operation [...
35.205: no vm operation [...
39.206: no vm operation [...
40.206: no vm operation [...
41.206: no vm operation [...
46.207: no vm operation [...
A little time spent with your favourite search engine will yield up the information that 'no vm operation' is the output produced when the runtime forced a safepoint.
Further searching revealed that the frequency of these forced safepoints can be controlled with the following flags:
-XX:+UnlockDiagnosticVMOptions -XX:GuaranteedSafepointInterval=300000
This command instructs the runtime to only guarantee a safepoint every 300 seconds, and since the duration of my test is less than that, there should be no forced safepoints. The default interval can be discovered by running the following command:
]$ java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal 2>&1 | grep Safepoint
intx GuaranteedSafepointInterval = 1000 {diagnostic}
Running my test tool with these settings removed the 100us jitter, so I'm just left with 50us introduced by the OS and hardware.
As mentioned in some of the mailing lists I stumbled across, it's probably not a good idea to stop the JVM from performing cleanup that requires a safepoint. For this testing tool however, it helps to remove a source of uncertainty that was dominating the jitter produced by the OS.
Update
At LMAX we run a number of microbenchmarks to ensure that our code does not suffer any regressions in performance. By their very nature, these tests tend to have a fair amount of noise in terms of single-shot execution time.
I applied the previously mentioned flags to the JVM running the tests; the reduction in the max execution time is clearly displayed in the chart below:
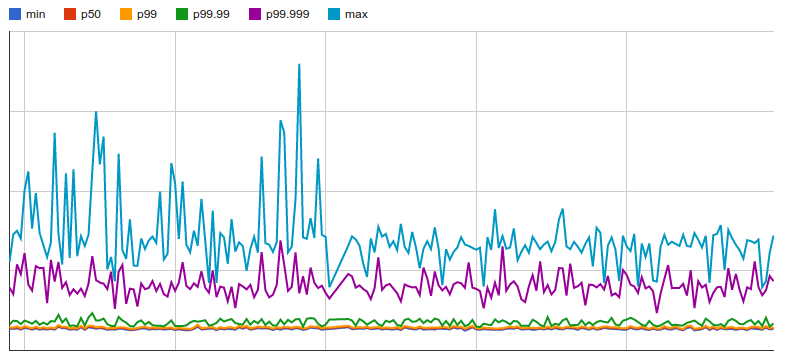
So aside from just being a curiosity for those who like digging into JVM internals, these flags could have a real benefit for reducing noise in benchmark tests.
Tests were performed using Oracle JDK 1.8.0_20.
Follow @epickrram